Image
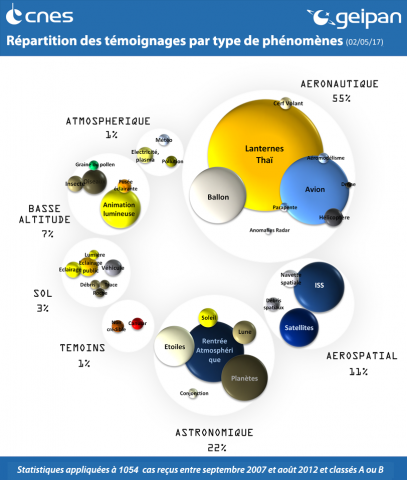
Since 2016 the GEIPAN uses "dynamic" statistics. They are calculated with the data related to classified cases that are published on the website all years combined.
This diagram displays and counts published GEIPAN testamonies. Files in progress will only be counted once completed.
Region names were not updated to maintain historical continuity in the calculation of case numbers by region.
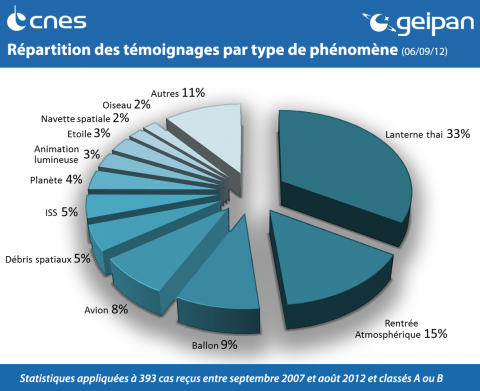
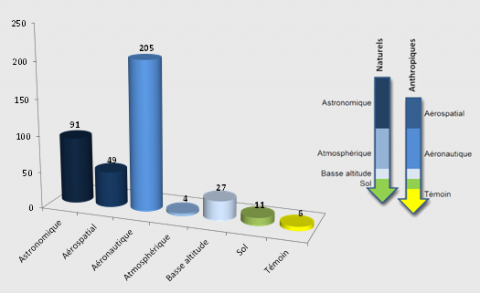
Below are listed the main types of identified phenomena according to their spatial range (from space to the ground) and according to their origin (natural or human). UAP's that are classed as type C or D (D1/D2) correspond to phenomena whose nature is not known and are therefore not included in the statistics below. These statistics correspond to cases received between September 2007 and August 2012.